Protecting Your Brand in the Agentic Internet: Balancing Access and Security
Protecting Your Brand in the Agentic Internet: Balancing Access and Security
Short answer
The agentic internet forces brands to solve two problems at once. They need to remain visible to AI systems that influence discovery, comparison, and buying decisions, while also protecting their sites from scraping, account abuse, and automation-driven fraud.
That balance requires a more precise approach than broad blocking. The goal is no longer to stop all non-human traffic. The goal is to distinguish between useful AI access, neutral machine activity, and automation that creates risk.
Why this matters now
For a long time, many companies could treat website security and discoverability as separate concerns. Marketing teams wanted visibility. Security teams wanted control. The overlap existed, but it was limited.
That is changing. AI systems now sit closer to the customer journey. They influence product discovery, summarize brand information, compare options, and increasingly interact with websites more directly. At the same time, the same automated infrastructure that makes agentic experiences possible also expands the attack surface.
This is why the agentic internet creates a real strategic tension. If you lock down your site too aggressively, you may reduce AI visibility, answer-engine presence, and future agent-mediated demand. If you stay too open, you may invite scraping, account misuse, and forms of automation that degrade trust, security, and decision quality.
The new problem: access and risk now move together
The central problem is simple: the same web that must stay accessible to AI systems also has to stay defensible.
That was easier when crawlers mostly read pages and bots looked obviously abusive. It is harder now because modern AI agents are not limited to passive crawling. They can navigate, compare, fetch information dynamically, and in some cases interact with account or commerce-adjacent flows.
This changes the security model. A machine session can no longer be judged only by whether it is automated. It must be judged by what it is trying to do, how far it is allowed to go, and whether that activity reflects legitimate user intent or suspicious behavior.
Why scraping is becoming a bigger brand risk
Scraping is no longer just a bandwidth problem. It is now a brand problem, a pricing problem, a data problem, and in some cases a strategy problem.
As scraping activity rises, the impact goes beyond infrastructure costs. Scrapers can extract product information, pricing, inventory patterns, content structure, documentation, and competitive signals. They can distort how your brand is represented elsewhere, weaken your control over distribution, and create noise in analytics and monitoring systems.
This matters even more in the AI era because scraped information can circulate through secondary layers. What begins as extraction can later influence summaries, comparisons, and recommendations generated somewhere else. That means scraping can affect not only security posture, but also how your company is interpreted across the wider AI ecosystem.
Why account takeover risk is getting more complicated
Account takeover is one of the clearest examples of how the line between helpful automation and hostile automation is becoming harder to manage.
In older models, suspicious login behavior, post-login automation, and rapid navigation patterns were often easier to classify as abuse. But as agentic systems become more capable, some legitimate activity may start to resemble the same patterns. A system acting on behalf of a user can move quickly, repeat structured actions, and operate continuously.
That does not reduce the risk. It increases the classification problem.
This is why post-login security needs to become more context-aware. It is no longer enough to ask whether behavior looks automated. Teams also need to ask whether the automation is authorized, trusted, bounded, and aligned with a valid user-driven workflow.
Why “block all bots” is no longer a serious strategy
A blanket anti-bot posture is becoming less viable in the agentic web.
Some machine access is strategically useful. Retrieval bots support AI visibility. User-triggered fetchers may be tied directly to real buyer questions. Some forms of structured automation may become part of how people browse, compare, and purchase online.
If a brand blocks everything non-human, it may protect itself from some abuse, but it may also reduce discoverability, disrupt future-ready user experiences, and cut itself off from emerging channels of demand.
The better model is selective access with trust-aware controls.
That means allowing some machine behaviors, rejecting others, and setting different thresholds depending on what part of the site is being accessed and what the system is trying to do.
The right mental model: classify, govern, verify
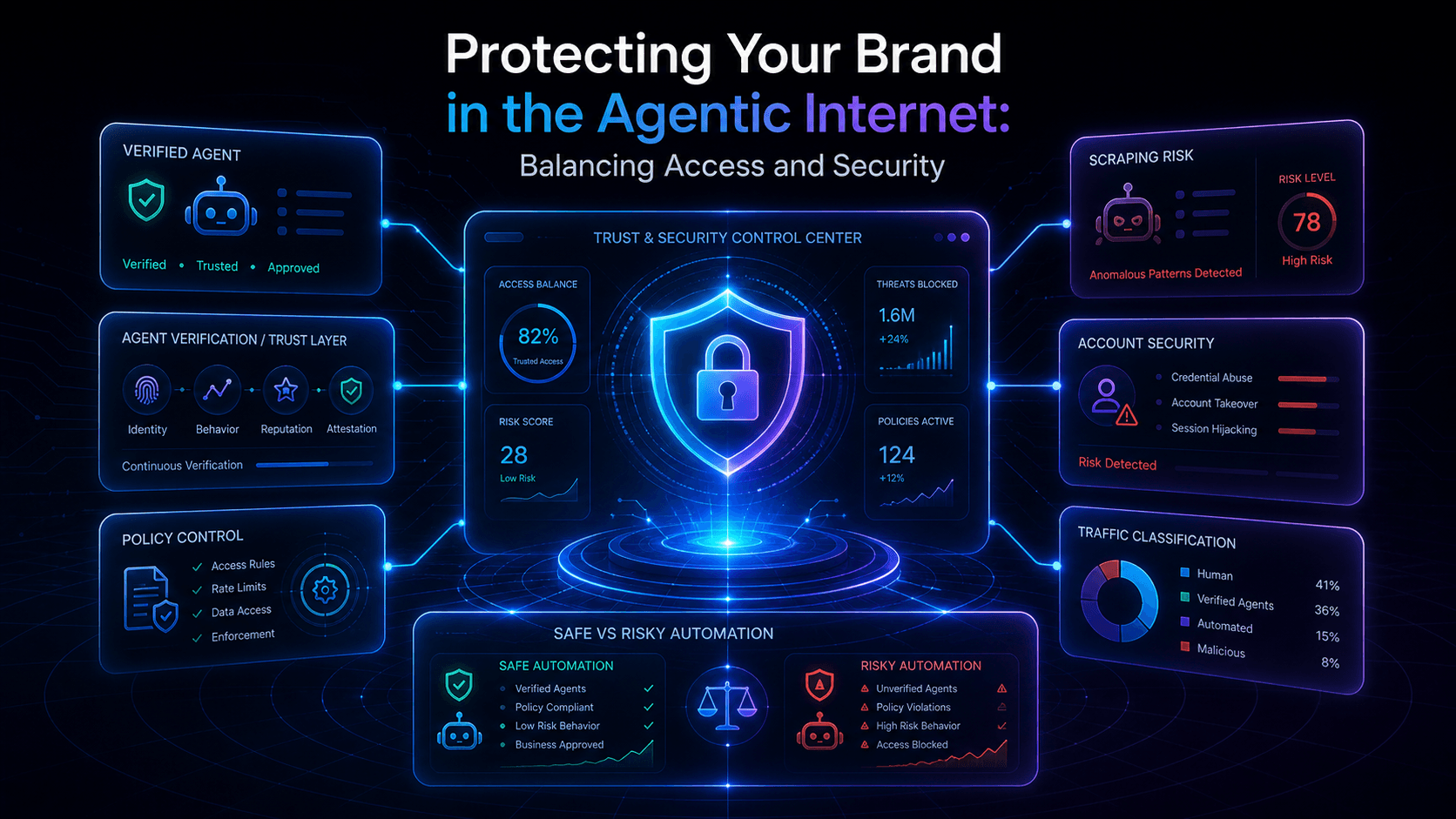
To operate safely in the agentic internet, brands need a more mature control model built around three verbs.
1. Classify
You need to distinguish between:
- traditional crawlers,
- AI retrieval systems,
- user-triggered AI fetchers,
- AI agents acting on behalf of users,
- suspicious automation,
- clearly malicious traffic.
Without that classification, every control becomes too broad or too weak.
2. Govern
Once traffic is classified, policy must follow intent. Public informational content may deserve one kind of access model. Sensitive workflows such as login, account management, pricing logic, or checkout deserve another.
Governance means deciding who can access what, under which conditions, and with what level of trust. It also means defining what “allowed automation” actually means for your business.
3. Verify
Trust cannot be assumed. It has to be tested continuously. A declared agent identity is not enough on its own. Teams need to observe behavior, evaluate consistency, and monitor whether activity stays inside the boundaries it claims to respect.
That is where traffic intelligence becomes essential. Security in the agentic internet is no longer just about static rules. It is about ongoing interpretation.
What a trust layer for AI agents should do
This is where tools like AgenticTrust represent an important shift in thinking.
The old model was mostly defensive. Detect the bot, block the bot, move on.
The newer model introduces a trust layer. Instead of assuming all agentic traffic is either good or bad, the system tries to understand what the agent is doing, how trustworthy it is, where it is acting, and whether those actions should be allowed.
A trust-oriented control layer should help answer questions like:
- Is this AI agent acting on behalf of a user or acting independently?
- Is it browsing, retrieving, transacting, or attempting to escalate access?
- Does its behavior align with an approved use case?
- Should it be allowed to continue, be restricted, or be blocked?
- Is the interaction useful to the business, neutral, or risky?
That shift matters because trust is becoming the real control surface of the agentic web.
What brands should protect first
Not every part of the website carries the same risk. Some surfaces are more exposed than others and deserve stronger control logic.
The highest-priority areas usually include:
- login and authentication flows,
- account pages,
- sensitive forms,
- pricing and availability logic,
- checkout and transactional flows,
- API endpoints,
- internal search and high-value content hubs.
These are the places where helpful automation and harmful automation may look structurally similar while creating very different outcomes.
Brands should also protect the integrity of public-facing content that shapes AI interpretation. If content is scraped, fragmented, copied, or misrepresented across external systems, the problem is not only security. It is also narrative control.
How to balance AI visibility with stronger defenses
The right balance usually does not come from a single file or rule set. It comes from layering controls.
A practical approach often includes:
- keeping important public content accessible for legitimate retrieval,
- separating retrieval access from more sensitive workflows,
- tightening controls as sessions move closer to authenticated or transactional surfaces,
- monitoring machine behavior rather than relying only on declared identity,
- using policy and trust signals together rather than broad allow/block logic,
- reviewing whether AI-visible content is also creating new scraping exposure.
This is where many teams go wrong. They manage AI visibility and security as separate streams of work. In reality, they are now part of the same operational system.
Why this is also a brand issue, not just a security issue
If your company is represented through AI systems, then security decisions now affect brand outcomes.
Too little control can lead to scraping, misuse, polluted analytics, and distorted summaries. Too much restriction can reduce discoverability and weaken your presence in AI-assisted journeys.
That means this is not only a SOC or infrastructure topic. It is also relevant for marketing, product, growth, and commerce teams. The agentic internet changes how users find brands, how they evaluate them, and how machine systems interact with the digital experience itself.
Protection and visibility now have to be designed together.
Where a broader signal layer helps
This is where a platform like Travatar becomes strategically useful.
Security tools may identify risk. Visibility tools may identify mentions. But Travatar helps connect those layers with website reality: who is visiting, what kind of automation is involved, how AI systems interact with your content, and whether the resulting signal is clean enough to support decisions.
That matters because in the agentic internet, security without interpretation is too blunt, and visibility without traffic intelligence is incomplete. A broader signal layer helps brands understand where AI access is beneficial, where it becomes risky, and how those patterns affect both visibility and trust.
Final takeaway
The agentic internet does not reward brands that choose between openness and security. It rewards brands that learn how to manage both at the same time.
The real challenge is no longer simply detecting bots. It is deciding which automation deserves access, which deserves limits, and which should be stopped entirely.
The brands that succeed will not be the ones that block the most. They will be the ones that classify better, govern more precisely, and build stronger trust layers for the new machine-mediated web.